Exposing Kinesis Streams over HTTP using Server-Sent Events (SSE)
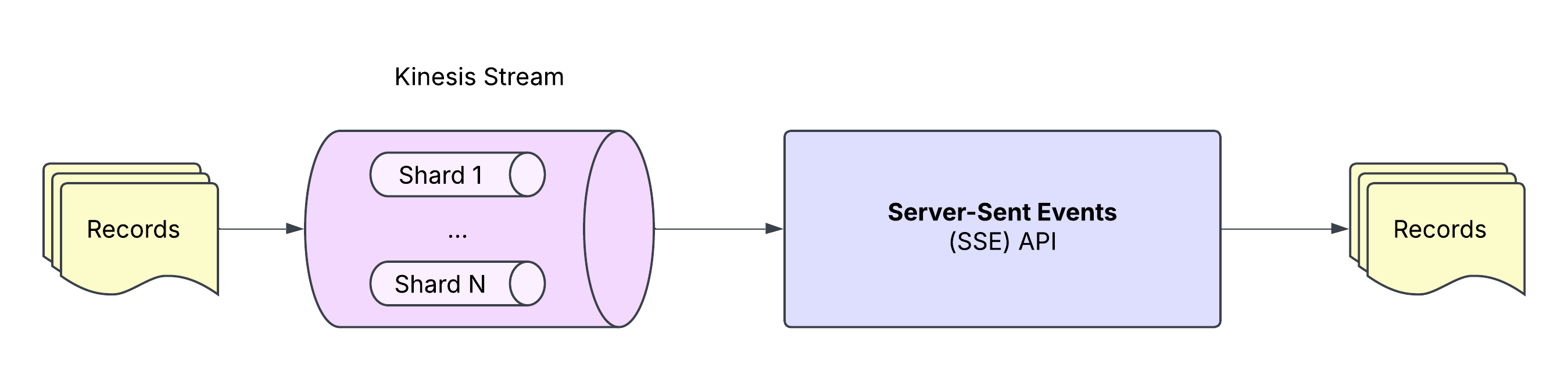
I previously described building an application which consumes events from a Kinesis Stream. Instead of using the Kinesis Client Library (KCL) for TypeScript, I exposed the stream over HTTP using Server-Sent Events (SSE) and coded against the EventSource API. Why?
-
KCL consumer applications are complex. They coordinate using a lease table (DynamoDB), they count against their streams' registered consumers quota, and the official KCL implementations depend on Java. Each point contributes to complexity developing, testing, and deploying KCL-based applications.
-
SSE and EventSource are simple web standards. The technology is well-supported across languages, and the EventSource API isolates applications from the specifics of Kinesis (no need to coordinate, register stream consumers, or integrate with KCL). Setting up a test SSE endpoint is simple, too.
-
We can evolve both ends of the pipeline independently. On the consumer side, we can add as many consumer applications as we like (at Propel, we used SSE for both applications and observability). On the producer side, we can swap Kinesis for Kafka or another technology, so long as we continue to provide an SSE adapter.
This isn't a completely new idea. The Wikimedia Foundation does something similar for Kafka. And while I don't expect this technique to perform well for high-throughput streams, it's a great technique for small and medium Kinesis Streams. It also obviates the need for tools like kinesis-tailf (just curl the SSE endpoint).
So are you curious? Great! I've made the project — dubbed "kinesis2sse" — open-source here: https://github.com/markandrus/kinesis2sse. In the rest of this post, I'll talk about usage, how it works, deployment, and future directions for the project.
Usage
First, set up a Kinesis Stream, "my-stream":
aws kinesis create-stream \
--region eu-central-1 \
--stream-name my-stream
Then, expose the stream at "/my-events" using kinesis2sse:
kinesis2sse \
--region eu-central-1 \
--routes '[{"stream":"my-stream","path":"/my-events"}]'
Start curl-ing http://localhost:4444/my-events:
curl localhost:4444/my-events
Finally, publish a test event to the stream:
aws kinesis put-record \
--region eu-central-1 \
--stream-name my-stream \
--data $(echo -n "{\"time\":\"$(date -u +"%Y-%m-%dT%H:%M:%SZ")\",\"detail\":{\"hello\":\"world\"}}" | base64) \
--partition-key 123
You should see the curl return the following:
:ok
data: {"hello":"world"}Note that kinesis2sse loosely follows the CloudEvents spec: records should arrive as JSON-formatted objects with an ISO 8601-formatted timestamp in the "time" property; the actual record data should arrive under a "detail" property. The actual logic for this is implemented here.
When you are done, delete the Kinesis Stream:
aws kinesis delete-stream \
--region eu-central-1 \
--stream-name my-stream
EventSource API
In your web browser, construct an EventSource and register a "message" event handler. Notice that we're setting the
since query parameter to "10m" — more on that later.
const eventSource = new EventSource('http://localhost:4444/my-events?since=10m')
eventSource.onmessage = event => {
console.log(event.data)
}
When you execute this, you should see {"hello":"world"} printed to the console.
If you are in a Node.js environment, take a look at the eventsource NPM package.
Parameters
start
When you start kinesis2sse, you can pass a start argument for each of the routes. This controls from where in each
stream kinesis2sse starts reading. Records appearing earlier than the start parameter will not be read. The parameter
accepts
- an ISO 8601 timestamp, like "1970-01-01T00:00:00.000Z".
- a duration subtracted from the current timestamp, like "1h" for "1 hour ago".
- "TRIM_HORIZON".
- "LATEST".
since
Similarly, when you curl the SSE API or use the EventSource API, you can pass a since query parameter. The since
query parameter controls from where to resume reading records. Naturally, since should always come sooner than
start.
capacity
Finally, capacity controls how many records kinesis2sse will store in memory. When you start kinesis2sse, you can pass
a capacity argument for each of the routes. In order to set this, you can do some back-of-the-napkin calculations
dividing available memory by average record size. Make sure to experiment.
How it works
Typical KCL consumer applications
Typical KCL consumer applications are distributed. For example, if our stream contains 4 shards, we might run 2 instances running 2 workers each, for a total of 4 workers. In order for workers to determine which shard to work on, they coordinate using a lease table in DynamoDB:
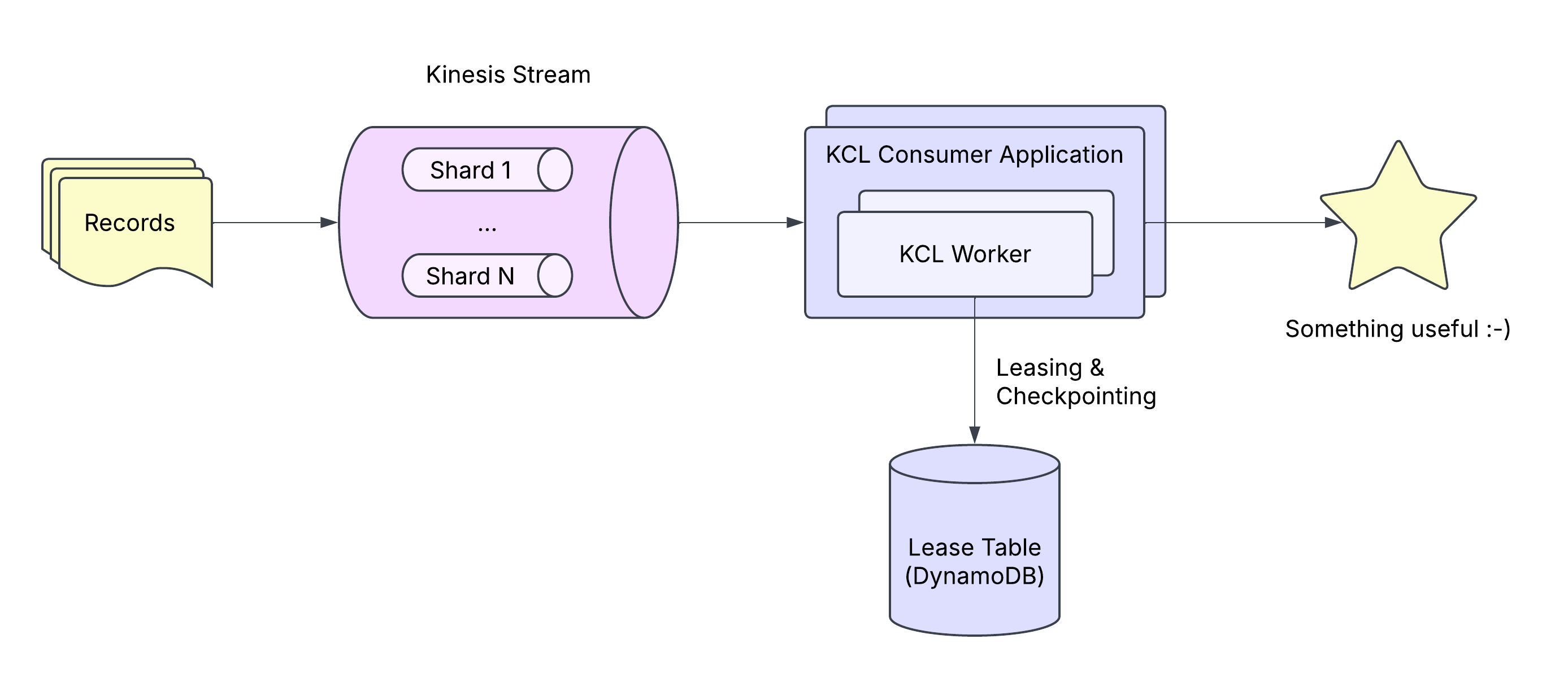
This architecture enables KCL consumer applications to scale horizontally for high-throughput streams with many shards. As shards increase, we can add instances and workers.
kinesis2sse
kinesis2sse differs from typical KCL consumer applications in that it doesn't aim for horizontal scalability. Instead, each instance subscribes to all shards of the stream in order to expose a complete set of records via SSE. For this reason, it doesn't need a lease table in DynamoDB; instead, it implements an in-memory Checkpointer:
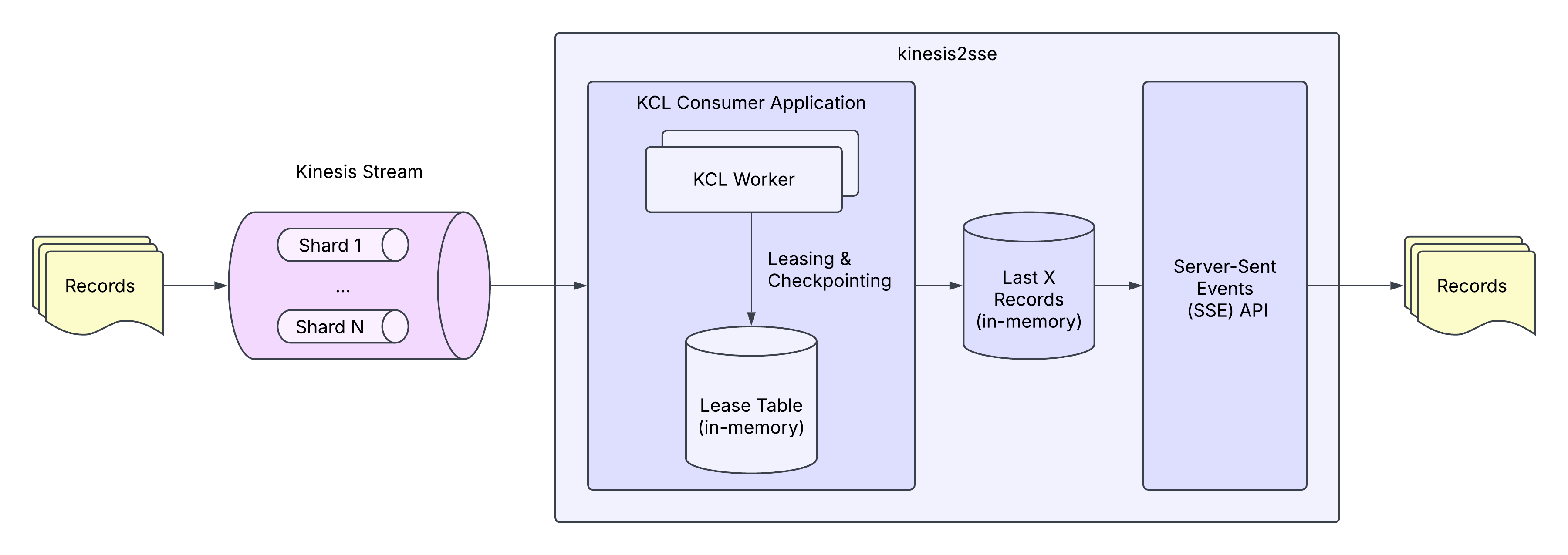
Additionally, kinesis2sse stores a configurable number of records in memory, using memlog. memlog is a simple in-memory, append-only log inspired by Kafka, which allows us to write records and read records at particular offsets:
ml, _ := memlog.New(ctx) // create log
offset, _ := ml.Write(ctx, []byte("Hello World")) // write some data
record, _ := ml.Read(ctx, offset) // read back data
fmt.Printf(string(record.Data)) // prints "Hello World"
In order to support reading records at a particular timestamp, kinesis2sse maintains a data structure, Timestamp2Offset. The data structure contains a B+ tree mapping timestamps to offsets, enabling us to look up the earliest offset for a particular timestamp.
RecordProcessor keeps the memlog and Timestamp2Offset data structures in sync as the workers consume records from the stream.
SSE API
When an HTTP request arrives to the SSE API, we
- Cast its
http.ResponseWriterto anhttp.Flusher. - Parse its "since" parameter and look up its offset, defaulting to the latest offset.
- Set the response's content-type to "text/event-stream" and flush the message ":ok".
- Start streaming memlog records from the offset.
- Flush each record with the "data:" prefix.
This is implemented in Service.
Deployment
At Propel, we successfully deployed kinesis2sse in both ECS and Kubernetes in 2- and 3-replica configurations behind a
load balancer. We guaranteed 24 hours worth of records, so we aligned the Kinesis Streams' retention and the kinesis2sse
start argument to ensure that, even if we lost an instance, it could come back and rebuild its local history.
Future directions
Here are some features that I think would be cool to implement:
- Pluggable authentication and authorization. The original version of kinesis2sse integrated with Propel's authentication and authorization system. I removed this functionality for the open-source version. It would be cool to re-introduce pluggable, per-route authentication and authorization in a generic way.
- Record-level transformations and filters. For example, we could filter out records that users are unauthorized to view on a per-request basis, or we could omit or materialize properties in order to maintain API compatibility with an event schema. We might even support client-supplied filters.
- An explicit
windowparameter to complementcapacity. Currently, you can only indirectly ensure that a window of records — e.g., 24 hours — is available by setting an appropriately highcapacity. It would be useful to support an actualwindowparameter and alert ifcapacityor memory is insufficient to maintain the window. - Improve metrics for observability. At Propel, we never pushed the limits of this system, because it was relatively low-traffic; however, in order to operate and tune kinesis2sse for higher scale, we'd want to know things like oldest record in the memlog, ingestion rate, average record size, etc.